Balancing the Imbalance: SMOTE and Synthetic Data Face Off
Imbalanced datasets skew ML models, hurting minority class performance. SMOTE interpolates minority samples, while synthetic data (GANs, VAEs) offers broader solutions. Compare strengths, weaknesses, and use cases—choose SMOTE for simplicity or synthetic data for privacy, scalability, and realism.

Introduction
Imbalanced Datasets: Not All Datasets Are Equal
In many real-world classification problems—such as fraud detection, medical diagnosis, or rare event prediction—datasets are imbalanced, with one or more classes significantly underrepresented. This skews machine learning models toward the majority class, often resulting in high overall accuracy but poor minority class performance. Since the minority class is often the critical focus, addressing imbalance is essential to building fair, reliable, and effective models.
The Challenge of Imbalanced Datasets
Across many machine learning tasks—especially classification—class imbalance leads to biased predictions and overlooked rare events. Two common techniques to address this are SMOTE (Synthetic Minority Over-sampling Technique) and broader synthetic data generation methods, each with unique strengths and trade-offs. SMOTE interpolates between minority class samples to improve model robustness, while synthetic data techniques—like GANs, VAEs, and rule-based generators—not only rebalance data but also address privacy, cost, and scalability. This article compares SMOTE and synthetic data generation, exploring when to use each through their advantages, challenges, and real-world applications.
SMOTE: A Closer Look
What It Is
SMOTE (Synthetic Minority Over-sampling Technique), introduced by Chawla et al. (2002), addresses class imbalance by generating synthetic minority class examples through interpolation between existing instances and their nearest neighbors in feature space. This approach encourages classifiers to form broader, less specific decision regions for the minority class, enhancing generalization and reducing overfitting compared to traditional over-sampling methods. Empirical results show that combining SMOTE with majority class under-sampling leads to improved classifier performance, particularly in terms of the area under the ROC curve (AUC).
How It Works
-
Select a Minority Class Sample: For each minority instance, SMOTE finds its k nearest neighbors (commonly k = 5) from within the minority class.
-
Random Neighbor Selection: For each minority instance, depending on the desired amount of over-sampling, randomly select one or more neighbors from its k nearest neighbors.
-
Interpolation: A synthetic sample is generated by interpolating between the selected instance and its neighbor. This is done by:
1. Taking the difference between their feature vectors,
2. Multiplying that difference by a random number between 0 and 1,
3. Adding the result to the original instance’s feature vector. -
Repeat as Needed: This process continues until the desired level of over-sampling is achieved.
This synthetic generation allows the classifier to learn broader and more general decision boundaries, enhancing its ability to detect minority class examples effectively.
Strength & Weakness
| Criteria | Strength | Weakness |
|---|---|---|
| Class Imbalance Handling | Highly effective at balancing datasets with skewed class distributions | Less effective when the minority class is extremely sparse or lacks a clear structure |
| Sample Quality & Diversity | Generates diverse, non-duplicate synthetic data points, helping to capture a richer data distribution | Can lead to overgeneralization where synthetic samples might not accurately represent the minority class, introducing noise |
| Data Compatibility & Implementation | Simple to integrate into machine learning workflows using tools like imbalanced-learn | Primarily suited for continuous (numerical) data; requires modifications (e.g., SMOTE-NC) to handle categorical data |
| Model Impact | Provides more representative training data that can enhance overall model generalization | If misapplied, it can contribute to overfitting—especially when used with complex models |
Real-World Applications
-
Cardiovascular Disease Prediction
Apostolopoulos (2020) applied SMOTE to the Z-Alizadeh Sani dataset for non-invasive coronary artery disease (CAD) diagnosis. The synthesized minority instances improved the performance of models like Neural Networks, Decision Trees, and SVMs, demonstrating SMOTE’s situational value in medical data—though dataset-specific validation remains essential. -
Credit Card Fraud Detection
Carcillo et al. (2018) proposed the SCARFF framework, which combines SMOTE with tools like Kafka, Spark, and Cassandra for real-time fraud detection. By correcting class imbalance, SMOTE boosted the scalability and accuracy of models analyzing high-volume streaming data. -
Intrusion Detection in Cybersecurity
Alshamy and Akcayol (2024) used SMOTE on the NSL-KDD dataset, enhancing Random Forest performance in both binary and multiclass intrusion detection. The study highlights SMOTE’s role in improving cybersecurity models by mitigating imbalance.
Synthetic Dataset Generation: Beyond SMOTE
While SMOTE focuses on generating synthetic minority class samples by interpolating within the existing feature space, synthetic dataset generation encompasses a broader range of techniques that aim to create entirely new data points, often capturing more complex patterns and distributions. These methods go beyond simple oversampling to produce synthetic data that can serve multiple purposes—balancing datasets, enhancing privacy, reducing data collection costs, or augmenting datasets with rare or sensitive cases.
At its core, synthetic data generation involves building a model of the original data distribution and then sampling new, artificial examples from this model. The generation process can be driven by different methodologies, broadly categorized as follows:
1. Generative Adversarial Networks (GANs)
GANs consist of two neural networks: a generator that creates synthetic data and a discriminator that evaluates its authenticity. Through iterative training, the generator learns to produce data indistinguishable from real data, making GANs suitable for generating high-fidelity images, text, and tabular data. Variants like Conditional GANs and Differentially Private GANs have been developed to cater to specific requirements, such as incorporating class labels or ensuring privacy (Shi et al., 2025).
2. Variational Autoencoders (VAEs)
VAEs are probabilistic models that learn the underlying distribution of data through an encoder-decoder architecture. They are particularly effective in generating continuous data and can be adapted for tabular datasets. VAEs offer advantages in generating diverse data points and are often used in applications requiring smooth interpolations between data points.
3. Rule-Based Synthetic Data Generation
This approach involves creating synthetic data based on predefined rules and logic that mimic the relationships and constraints of real data. While it offers high control and consistency, especially for structured data, it may lack the complexity and variability found in real-world datasets. It's particularly useful for generating data that adheres to specific formats or regulatory requirements.
4. Gaussian Copula Models
Gaussian Copula models are statistical methods used to generate synthetic data by capturing the dependencies between variables. They are effective in preserving the correlation structure of the original data, making them suitable for generating tabular datasets with complex interdependencies (Houssou et al., 2022).
5. Transformer-Based Models
Transformer models, originally designed for natural language processing tasks, have been adapted for synthetic data generation across various domains. These models excel in capturing complex dependencies and patterns within data, making them suitable for generating realistic synthetic datasets.
6. Hybrid Approaches
Combining multiple techniques can leverage the strengths of each. For instance, integrating rule-based methods with machine learning models can produce synthetic data that is both realistic and adheres to specific constraints. Hybrid approaches are increasingly utilized to balance control, realism, and scalability in synthetic data generation.
Strength & Weakness
| Criteria | Strength | Weakness |
|---|---|---|
| Application Versatility | Addresses various data challenges beyond class imbalance, including privacy protection, cost reduction, and scenario simulation | Developing accurate and realistic synthetic data can be challenging, especially for complex or high-dimensional datasets |
| Privacy Preservation | Allows for analysis and model training without compromising sensitive information | If the original data contains biases, those biases can be reflected in the synthetic data. |
| Cost and Time Efficiency | Reduces the time and expense associated with collecting large real-world datasets | Synthetic data may fail to capture all the nuances of real-world data, potentially affecting model performance |
| Scalability | Enables the generation of large datasets to meet specific requirements, beneficial for extensive machine learning tasks | Advanced techniques, like GANs, can be computationally expensive |
Real-World Applications
-
Autonomous Driving – CARLA
Dosovitskiy et al. (2017) introduced CARLA, an open-source urban driving simulator that generates high-fidelity synthetic data with photorealistic environments, varied weather, traffic, and multiple sensor outputs. This data, paired with precise ground truth, supports training and benchmarking of autonomous driving models. -
Electronic Medical Records – medGAN
Choi et al. (2017) developed medGAN, a hybrid autoencoder-GAN framework for generating high-dimensional, multi-label discrete EMR data. The synthetic records closely approximated real data, achieving within 2% performance deviation on predictive tasks and showing low risk of identity or attribute leakage. -
Retail Simulation – RetailSynth
RetailSynth, proposed by* Xia et al. (2023)* simulates retail shopping behavior using a calibrated, multi-stage behavioral model based on grocery transaction data. It enables the evaluation of pricing, promotions, and recommendation algorithms with synthetic data that aligns closely with real revenue and retention metrics.
Decision Guide: Choosing Between SMOTE and Synthetic Data Generation
The diagram below serves as a decision guide for choosing between SMOTE and synthetic data generation, based on the specific requirements of your use case. It considers factors such as class imbalance, data type, privacy, and scalability to support informed and context-aware choices.
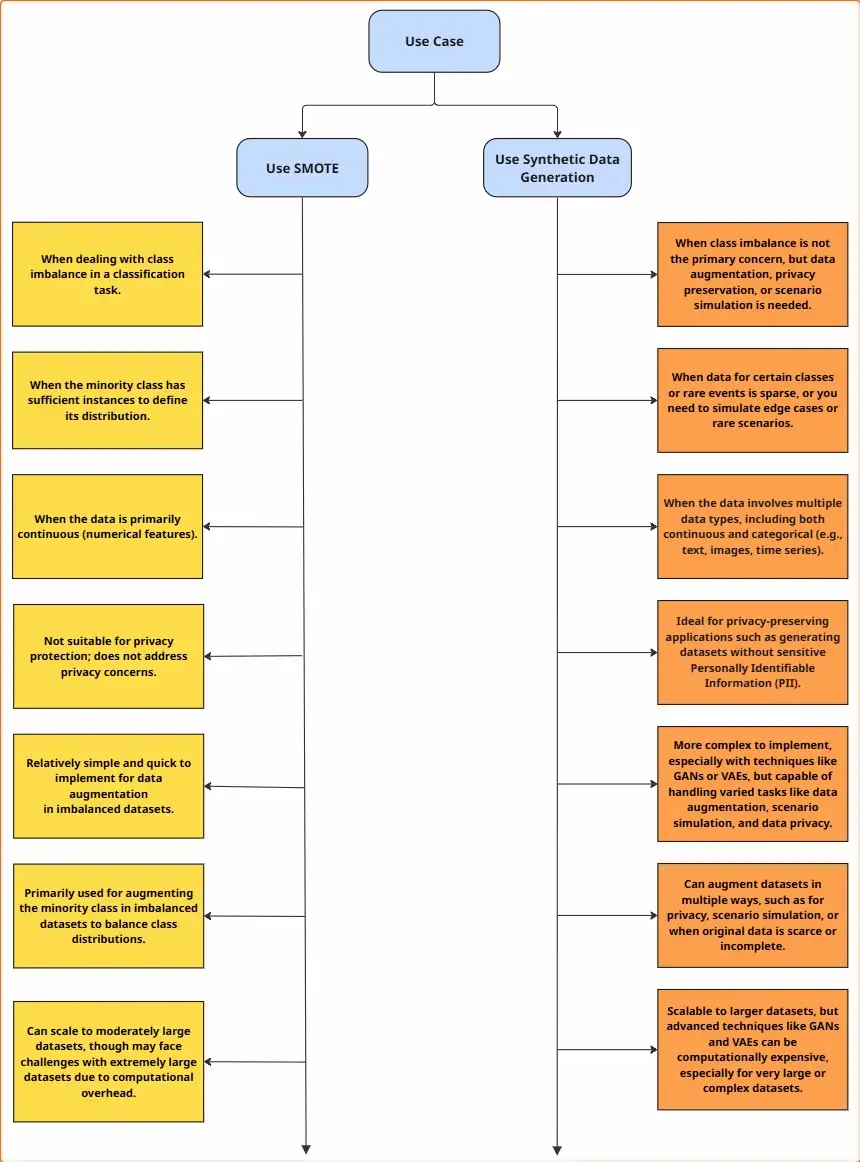
Conclusion: Tailoring the Solution to the Problem
Class imbalance is not a one-size-fits-all problem—and neither are its solutions. SMOTE offers a simple, interpretable, and effective way to address moderate class imbalance in continuous data, especially when improving classifier sensitivity without drastically altering data distribution. However, its scope is limited when data complexity, privacy, or generative realism are key priorities.
Broader synthetic data generation techniques—GANs, VAEs, and rule-based methods—unlock capabilities beyond resampling. They can simulate entire datasets, protect sensitive information, and create scalable training environments—but with higher computational and design complexity.
Ultimately, the choice between SMOTE and synthetic data depends on context: for mitigating imbalance in structured data with minimal overhead, SMOTE is often preferred; for generating rich, privacy-aware, or scalable data, synthetic methods take the lead. By understanding trade-offs and strengths, practitioners can select the best tool—ensuring balanced datasets and robust, responsible, future-ready machine learning systems.
References
- R. Alshamy and M. A. Akcayol, Intrusion Detection Model Using Machine Learning Algorithms on NSL-KDD Dataset, International Journal of Computer Networks & Communications (IJCNC), vol. 16, no. 6, 2024. Available: https://www.researchgate.net/publication/386249048_INTRUSION_DETECTION_MODEL_USING_MACHINE_LEARNING_ALGORITHMS_ON_NSL-KDD_DATASET
- I. D. Apostolopoulos, Investigating the Synthetic Minority Class Oversampling Technique (SMOTE) on an Imbalanced Cardiovascular Disease (CVD) Dataset, International Journal of Engineering Applied Sciences and Technology, vol. 4, no. 9, pp. 431–434, 2020. Available: https://doi.org/10.48550/arXiv.2004.04101
- F. Carcillo et al., “SCARFF: A Scalable Framework for Streaming Credit Card Fraud Detection with Spark,” Information Fusion, vol. 41, pp. 182–194, 2018. Available: https://doi.org/10.1016/j.inffus.2017.09.005
- N. V. Chawla et al., SMOTE: Synthetic Minority Over-sampling Technique, arXiv preprint arXiv:1106.1813, 2011. Available: https://arxiv.org/abs/1106.1813
- E. Choi et al., Generating Multi-label Discrete Electronic Health Records Using Generative Adversarial Networks, arXiv preprint arXiv:1703.06490, 2017. Available: https://arxiv.org/abs/1703.06490
- A. Dosovitskiy et al., CARLA: An Open Urban Driving Simulator, arXiv preprint arXiv:1711.03938, 2017. Available: https://arxiv.org/abs/1711.03938
- R. Houssou et al., Generation and Simulation of Synthetic Datasets with Copulas, arXiv preprint arXiv:2203.17250, 2022. Available: https://arxiv.org/abs/2203.17250
- R. Shi et al.,A Comprehensive Survey of Synthetic Tabular Data Generation, arXiv preprint arXiv:2504.16506, 2025. Available: https://arxiv.org/abs/2504.16506
- Y. Xia et al., RetailSynth: Synthetic Data Generation for Retail AI Systems Evaluation, arXiv preprint arXiv:2312.14095, 2023. Available: https://arxiv.org/abs/2312.14095
Author Name: Abinandaraj Rajendran
AI/ML enthusiast actively following and applying the latest innovations in Generative AI.


